

Vamos supor que você está usando o SQL Server 2005 no seu atual projeto, e você achou que algumas linhas com os dados iguais em todas as colunas. Vamos considerar que você tenha uma tabela com nome "Exemplo" e as colunas ID e Nome.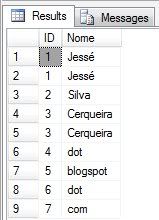
Você pode ver que os registros com nome Jessé e Cerqueira estão duplicados. A consulta abaixo retorna apenas os registros duplicados
SELECT
[ID],[NOME],COUNT([ID])
FROM
[Exemplo]
GROUP BY
[ID],[NOME]
HAVING
COUNT([ID]) > 1
Vamos supor que você precise excluir o registro com valor (1, 'Jessé'), de modo que apenas uma linha continue.
DELETE TOP(1) FROM [Exemplo] WHERE [ID] = 1
Usando o Top(1) é possível excluir apenas o primeiro registro, em situações como no exemplo acima, que tem apenas um registro a mais. Se você tiver várias linhas com valores duplicados, você tem que usar TOP (n-1) para que apenas 1 linha permaneça após o delete. Para apagar todos os registros duplicados que você precisa para escrever um cursor como no exemplo abaixo.
DECLARE @ID int
DECLARE @NOME NVARCHAR(50)
DECLARE @CONT int
DECLARE CUR_DELETE CURSOR FOR
SELECT [ID],[NOME],COUNT([ID]) FROM [Exemplo] GROUP BY [ID],[NOME] HAVING COUNT([ID]) > 1
OPEN CUR_DELETE
FETCH NEXT FROM CUR_DELETE INTO @ID,@NOME,@CONT
WHILE @@FETCH_STATUS = 0
BEGIN
DELETE TOP(@CONT -1) FROM [Exemplo] WHERE ID = @ID
FETCH NEXT FROM CUR_DELETE INTO @ID,@NOME,@CONT
END
CLOSE CUR_DELETE
DEALLOCATE CUR_DELETE
27 fevereiro 2009
[SQL SERVER] Deletando registros duplicados
Assinar:
Comentários (Atom)